
Channel Coding of Speech Signals in 3G Systems
Contents
Second-generation systems
Third-generation systems
Relationship between coding, interleaving and user equipment speed

In my last article, 3G: Packet Transmission in EDGE and UMTS FDD, I addressed packet transmission in evolutionary 3G systems, and in particular in EDGE and the UMTS FDD mode (aka IMT-DS). In this issue, I want to address the channel coding schemes used in 3G systems and in which respect they are different from the ones used in 2G systems. This month, we will look in particular at the coding and handling of speech signals.
Second-generation systems
The main purpose of second-generation systems such as GSM, IS-136, IS-95, or PDC was to enable efficient digital voice transmission. To that effect, the basic data rate was chosen to support a good voice quality- typically in the range of a few to 13 kbit/s, depending on the speech coder.
IS-95 uses a variable-rate speech coder, which output rate varies from frame to frame (20 ms). It can take any of the following values: 0.8, 2.0, 4.0, to 8.6 kbps. The gross rate (after addition of tail bits, etc.) can then be 1.2, 2.4, 4.8, or 9.6 kbps. This low data rate is then protected with a convolutional code of rate 1/2 on the downlink and of rate 1/3 on the uplink. It is interesting to note that all bits delivered to the physical layer by the speech coder are equally protected (with the same code).
This is not the case with standards such as GSM, IS-136, and PDC, where the speech coder delivers several streams of bits, organized in classes. Taking the example of IS-136 (it is very similar in GSM), there are class I bits and class II bits. The class I bits are convolutionally encoded (and some of them first protected by a CRC) while class II bits are transmitted without protection. A good explanation for it can be found in the following statement from the working group for speech coding: "the most efficient transmission of speech requires different levels of protection for different classes of coded bits. This is because of the inherent difference in error sensitivity of the coded bits" [1]. Hence, critical bits are better protected.
The picture below shows a block diagram of the IS-136 coding scheme.
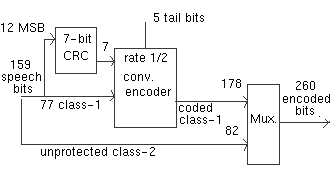
Let me mention that improvements in speech coding have played an important role in different standards. For example, GSM now supports a more efficient encoding scheme than the original 13 kbps. My focus here, however, is not on the speech coders but rather on the channel coders (convolutional, etc.) for speech signals.
Third-generation systems
Taking as an example the 3GPP Frequency Division Duplex component (also referred to as 3GPP-DS for "Direct Spread" or earlier W-CDMA), the basic entity is called a transport channel. Each transport channel is associated with a particular encoding scheme. This scheme may be 1/2-rate or 1/3-rate convolutional encoding or 1/3-rate turbo coding. This doesn't mean that an optimization of the encoding as in GSM or IS-136 (also called UEP or "Unequal Error Protection") is not feasible—in fact, it is actually part of the specifications.
The speech coder likely to be used is the AMR (Adaptive Multi-Rate) coder. The AMR coder delivers (up to) three classes of bits, which ought to be protected according to their importance.
The 3GPP-DS standard is, for that matter, quite flexible. First of all, each class can be mapped to a different "transport channel" and the 3 transport channels then multiplexed and transmitted on one resource (read: spreading code). This means that each class is encoded separately with specific parameters.
Let us now have a more detailed look at the possible parameters available for encoding. First of all, as we already mentioned, both convolutional and turbo coding are supported in 3GPP. It is however likely that speech signals will only make use of convolutional coding for several reasons:
- the requirements on the bit error rate is not as stringent as for data transmission
- speech signals should be received by low-end terminals (phones!), which may not include a turbo decoder
- convolutional coding is quite suitable for the protection of short blocks (less than 103 bits for any class per 20ms of speech [2])
Even though convolutional encoding is applied to all classes, the level of protection may be different. In particular, class A and B are protected with a 1/3-rate code while class C is protected with a 1/2-rate code. Besides, each transport channel is assigned a different rate-matching attribute, which essentially enables it to provide a higher Eb/N0 for channels with a higher importance (through unequal puncturing and repetition).
Relationship between coding, interleaving, and user equipment speed
The main objective of channel coding is to enable efficient error correction in the receiver. It is well known that the Viterbi decoder is the best decoder for convolutional codes. It, however, performs best when the errors are distributed throughout the whole block. For this reason, interleaving is introduced after the coder in order to spread the burst errors due to the fading channel across the coding block.
This technique achieves good results as long as the duration of the channel fade is small compared to the block length. This means that it achieves good results at high velocities, as the channel changes faster and never stays in a deep fade for a whole block.
At low velocities, however, the channel may fade during a whole block. In that case, the decoder cannot correct the errors. This means that power control is crucial at low velocities in order to compensate for the lack of interleaving diversity. Note that at high velocities, the power control mechanism doesn't work as well, but this drawback is compensated for by the gain provided by interleaving.
The picture below illustrates the interleaving gain at high speed vs. low speed (without power control). The block error rate (BLER) as a function of the transmitted energy is displayed in the COSSAP visualization tool environment.
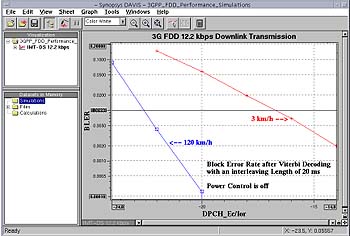
To conclude on this topic, I'll mention that it would be tempting to increase the block length in order to increase the benefit of interleaving. However, for speech signal, the delay in transmission and decoding should typically not exceed 100 ms, 40 ms of which are consumed for speech coding [1]. This means that the preferred interleaving depth should be 20ms and in no case over 40ms. Higher interleaving lengths (such as 80 ms) can only be used for non-time-critical signals such as data.
References
[1] http://www.3gpp.org - Document TSGS4#3(99)085 a.k.a. TSGR1#3(99)314
[1] http://www.3gpp.org - Document TS 26.101
Biography
Marc Barberis is a staff engineer at Synopsys in Mountain View, CA, where he is currently involved in the development of the Synopsys 3G Products. He has worked, among other areas, on the design of receivers for 2G wireless. He received an MS in electrical engineering from Ecole Nationale Superieure des Telecommunications, France. He can be reached at barberis@synopsys.com.